Rで2つの重回帰モデルをF検定で比較したときの結果の見方(実行例)
結論
2つの重回帰分析モデルのどちらがいいかは、F検定を用いて比較できる
anova(small_model, large_model)
を実行し、有意、つまりp値が低かったらlarge_modelを使うべき、高かったらsmall_modelを使うべき
コード例:
model1 <- lm(drivers ~ kms + PetrolPrice, data=Seatbelts) model2 <- lm(drivers ~ kms + PetrolPrice + law, data=Seatbelts) anova(model1, model2)
実行例
今回はRに元々ダウンロードされている「Seatbelts」というデータセットで例を確かめていく。Seatbeltsはイギリスの交通事故についての月別の時系列データである。
View(Seatbelts)
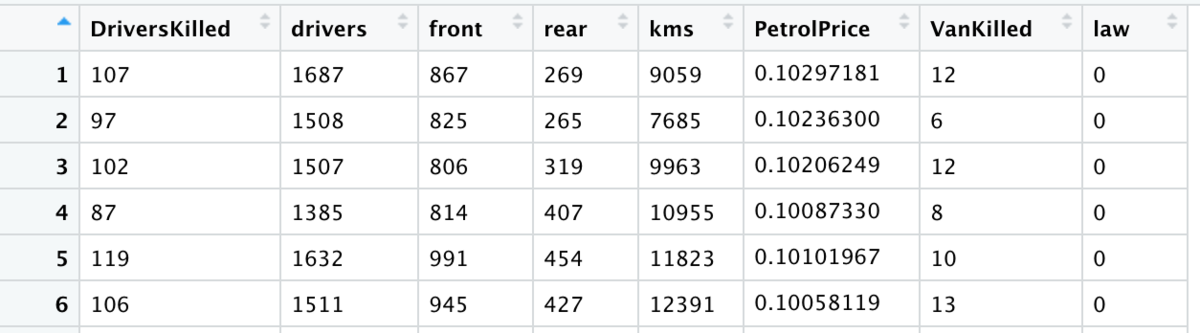
ちなみに今回使うSeatbeltsの変数は4つ:
- drivers:運転による月間死者数
- kms:国民全体の当月の自動車走行距離
- PetrolPrice:当月の平均ガソリン価格
- law:シートベルト着用義務の法律が施行された1983年以降は1、それより前は0
まずは2つの回帰式を考えていく
上をmodel 1, 下をmodel 2と呼ぶことにする。
Rでの実行↓
model1 <- lm(drivers ~ kms + PetrolPrice, data=Seatbelts) model2 <- lm(drivers ~ kms + PetrolPrice + law, data=Seatbelts)
つまり、運転による死者数は走行距離数などと、どう関係しているのかをここでは見ている。
ここで、model 1とmodel 2の違いは、lawの有無である。
model 2の方が優れていると判断されれば、lawをmodel 1に加えるべきと結論づけても良さそうだ。
どちらのモデルが優れているときにはF検定を使う。
F検定とは、以下の仮説検定を行うことである。
model 1の方が優れている
model 2の方が優れている
RでF検定を実行する際は、anova(small_model, large_model)とし、変数の少ない回帰式を最初に書く↓
anova(model1, model2)
すると、以下のような結果が表示される
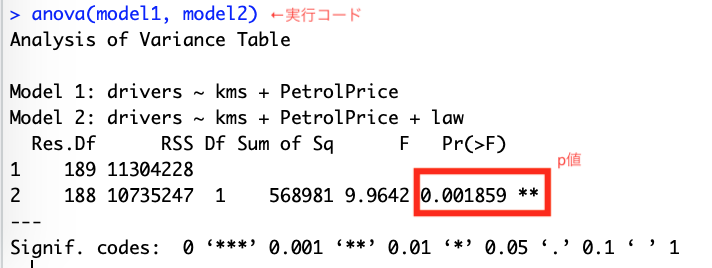
p値を確認すると、0.001859であった。これは5%より低いので、帰無仮説は棄却される。つまり変数lawを含んだmodel 2の方を使うべきである。
補足:
「結局法律変更で何かが変わることはわかったけど、法律は事故減少に役立ってるの?」への解答
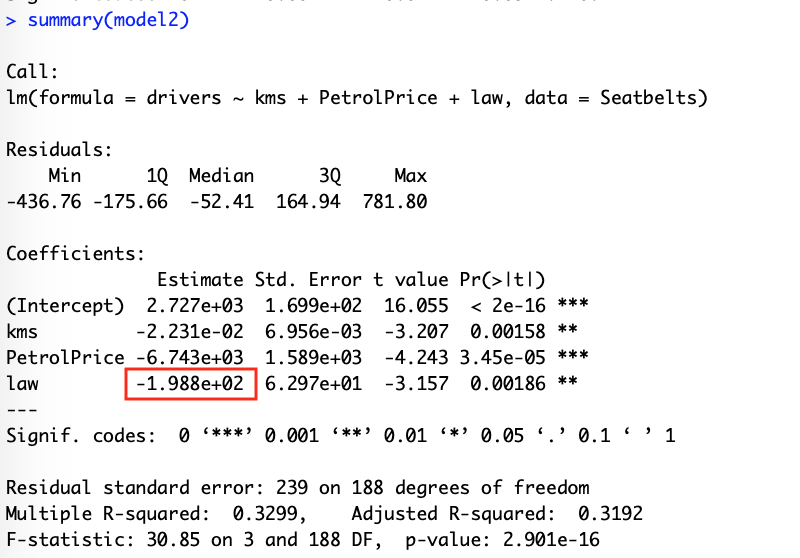 model 2の変数lawの係数は-1.988e+02で、負の値である。法律がある状態が
model 2の変数lawの係数は-1.988e+02で、負の値である。法律がある状態が なので、法律がある状態の方が事故が少ない。よって法律は事故減少に効果あり。
複数の変数をチェックする時、仮説検定は以下のようになる
のどれか一つ以上が成り立つ
今回は多重共線性や誤差相関などは無視している。